「Horse Empire」(奉国牧马)—— v1.0 公测版,全球上线。
谁小时候没幻想过拥有一群自己的马呢。给它取个名、喂它吃草、看它一点点长大——然后某天它当上了爸爸或妈妈,生下一匹小马驹。你凑过去一看:比它爸还精神。
现实里养不起马,那就在浏览器里养。割草、喂马、配种、繁殖,从几匹最普通的慢驹起步,慢慢育出良驹、千里驹、贡驹——直到某天,神驹降临。
这是一个古风牧场育成放置游戏。
「Horse Empire」(奉国牧马)—— v1.0 公测版,全球上线。
谁小时候没幻想过拥有一群自己的马呢。给它取个名、喂它吃草、看它一点点长大——然后某天它当上了爸爸或妈妈,生下一匹小马驹。你凑过去一看:比它爸还精神。
现实里养不起马,那就在浏览器里养。割草、喂马、配种、繁殖,从几匹最普通的慢驹起步,慢慢育出良驹、千里驹、贡驹——直到某天,神驹降临。
这是一个古风牧场育成放置游戏。
静态站点的内容保护是个尴尬的命题。
GitHub Pages、对象存储、CDN——纯静态托管便宜到几乎免费,可它们没有服务端。「想给某个页面加密码、只让特定人看」这个再普通不过的需求,通常意味着得引入后端:一份鉴权服务、一个登录态、可能还有数据库。为了一个密码框,把无状态的静态站点拖回有状态架构,不划算。
StaticShield 换了个思路:把加密下沉到产物本身。用密码把 HTML 加密成一份「自解密页面」,密文与解密逻辑都内嵌在同一个 .html 里;部署照旧是纯静态,访客输入密码后由浏览器端 WebCrypto 实时还原。全程零后端。
每天上班如上坟,下班躺平如咸鱼。焦虑的时候,总想找点东西敲一敲。
以前的人敲木鱼是为了静心,现在人没木鱼就敲键盘,于是我做了一个赛博木鱼:在手机和电脑上点一点,攒的不是烦恼,是赛博功德。
它叫 「赛博木鱼:功德无量Pro」(英文名 ZenIdle)——一个放置类(idle)小游戏,点一下功德 +1,挂着也会自己涨,最终目标是飞升成佛、功德圆满。
最近我做了一个实验,用了 Claude Code ,让 AI 自己从头到尾生成了一部都市种田网文。从建项目、写总纲和详细大纲,到逐章生成正文,全程 AI 独立完成。我不做任何人工修改,包括那些明显的错误和别扭的地方,全部原样保留。
结果就是这本书:《我在城市种田养鸡》——320 章,7 卷,约 78 万字。
小说的设定本身挺典型:38 岁失业男青年方远背了一身债,突然获得「农场系统」,在自家楼顶种出品质逆天的灵植,被人质疑、自证、打脸,最后建立城市农业帝国、收获爱情。
但接下来我要说的,才是这个项目的重点。
前阵子 DeepSeek-V4 系列模型正式发布了,我关注到的不只是参数规模(V4-Pro 总参数 1.6T),还有价格——百万 tokens 输出只要六块钱,输入命中缓存甚至只要两分五。这个调用成本,已经低到可以随便用了。
我每天早上都在纠结同一个问题:冰箱里的贝果明明还有好几天才过期,但每次都被新买的其他面包挤到最里面,最后放到过期才发现。周末囤的食材,周一早上翻半天找不着,最后还是只能叫外卖。
于是花了一个周末,基于 DeepSeek-V4 全系列模型(V4-Pro / V4-Flash 都支持)做了个小工具——Breakfast Manager(早餐管理应用),现在已经在Github上完整开源。
项目里最核心的 AI 能力就是调用 DeepSeek 的 API。用户先在后台填写身体数据:身高、体重、年龄、性别,还可以加上特殊要求,比如示例数据里的“减脂期,高蛋白低碳水”。
系统会结合你冰箱里现有的食材库存,调用 DeepSeek-V4 模型(默认使用 DeepSeek-V4-Pro)生成个性化的早餐建议。前端用的是流式输出,AI 的回答一个字一个字往外蹦,体验比干等几十秒舒服很多。
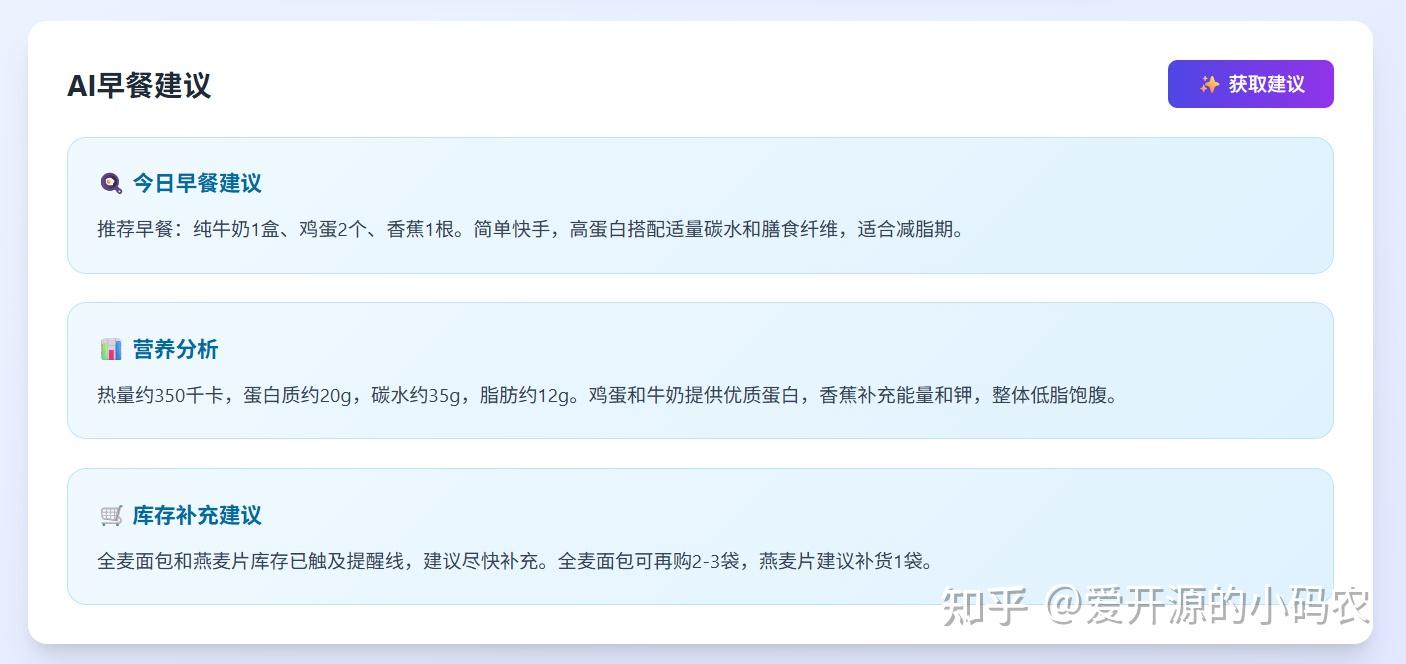
代码里同时预留了 V4-Pro 和 V4-Flash 的切换入口。如果你只是想随便玩玩,用 V4-Flash 成本几乎为零;如果希望营养建议更细致、逻辑更严谨,切到 V4-Pro 也就多花一两分钱。当然,其他支持OPENAI格式的API也都能接入。
只做个套壳的 API 调用网页太没意思了,我把前后端都搭了出来:
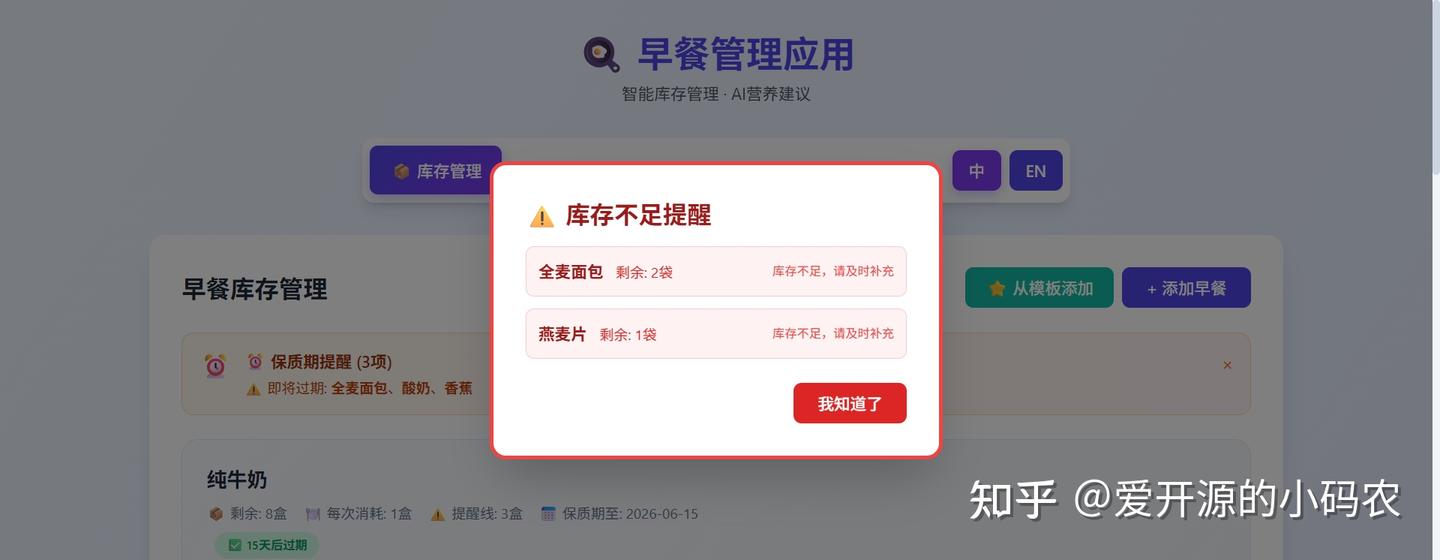
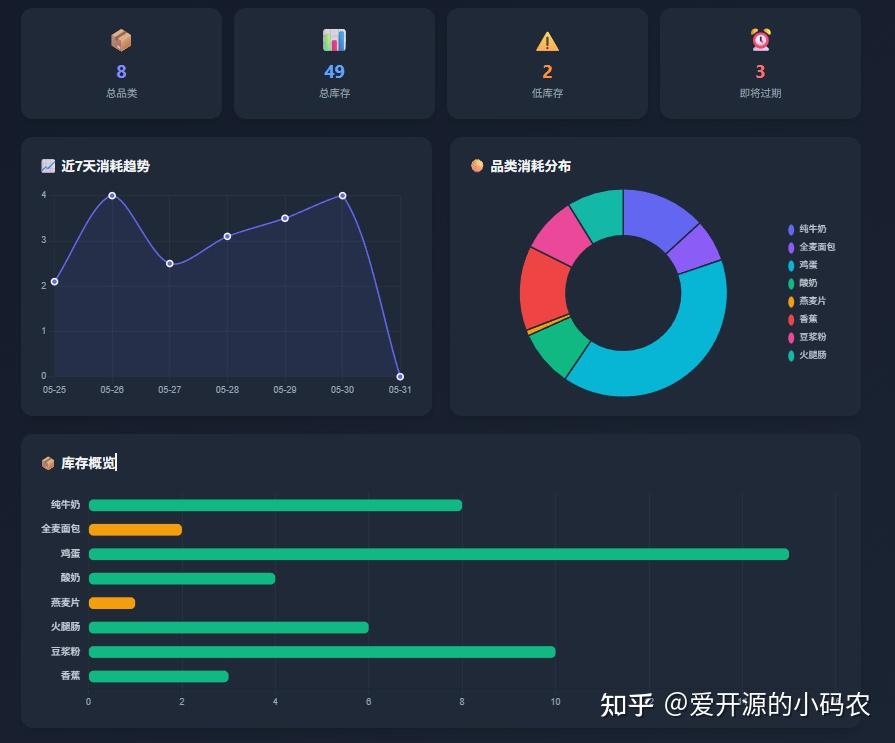
技术栈是 Node.js + Express + 原生 JavaScript + Tailwind CSS,数据直接存在本地 JSON 文件里,无需联网数据库,保证数据安全。
项目托管在 GitHub 上,整套命令如下(Node.js 安装过程略去):
1 | git clone https://github.com/wangshengithub/breakfast-manager.git |
启动之后浏览器访问 http://localhost:3000 就可以用了。
首次使用需要去 DeepSeek 开放平台申请一个 API Key,然后在网页后台填进去就行。按 V4 现在的定价,你一顿早餐的钱够调几百万次都说少了。
一方面是自己觉得确实能解决“冰箱里有东西却不知道吃什么”的痛点,就来分享给大家;另一方面也是希望如果你有兴趣,可以直接看代码学一下 Node.js + Express 的小项目是怎么组织的。如果你也经常为早餐发愁,或者厨房里总有食材放到过期,可以试试这个工具。代码很轻量,没有复杂依赖,运行起来就能用。
如果这个项目帮你省下了每天早上站在冰箱前纠结的几分钟,或者它的代码解决了你开发中的一些疑问——请在 GitHub 上给我点一个 Star ⭐️!
这是对我熬夜写代码最大的鼓励。
WSAI-Heart 发布后,我用同样的思路尝试了一个更大的版本。基座模型从 Qwen3.5-0.8B-Base 换成了 Qwen3.5-2B-Base,LoRA 训练层数也从 2 层增加到了 16 层。
心里话想说却不知道该告诉谁,这是很多人都有过的感受。
怕被嘲笑、怕被误解、怕说出来反而更难受。而网上的心理类 App,需要注册、需要联网,对话记录可能被存在服务器上。
如果有一个 AI,只运行在你自己的电脑上,不联网、不上传数据呢?